

By Christopher Allen & Shannon Appelcline
[This is the fourth in a series of articles on collective choice, co-written by my collegue Shannon Appelcline. It will be jointly posted in Shannon’s Trials, Triumphs & Trivialities online games column at Skotos.]
Last year in Collective Choice: Rating Systems we took a careful look at eBay and other websites that collect ratings, and used those systems as examples to highlight a number of theories about how to make rating systems more useful.
We suggested three main methods for improving rating systems:
Granular Ratings: Based on the clumping of ratings to high values, we believed that ratings could be made more useful by increasing the size of a rating scale. Most rating scales are 5-point ranges, so we suggested a 10-point range instead.
Distinct Ratings: Raters can be somewhat arbitrary in how they rate items, varying both from each other and even from themselves (usually over multiple sessions). Thus we believed that providing explicit statements of what each number meant could improve ratings.
Statistical Ratings: Finally we stated that in low volumes ratings could be biased by various quirks of data entry, either malevolent or not, and that ratings could be improved with strong statistical methods being used to polish up data and automatically keep “bad” data in line with “good”.
In the year since we wrote that article we’ve decided to practice what we preach and have rolled out an entirely new rating system called The RPGnet Gaming Index. We’ve applied all of the above theories and thus far it looks like they’re not only working, but that they’re actually providing better rating systems than previous ones we’ve used at the RPGnet site.
In this article we’re going to step through the data we’ve collected from this experience and see how it applies to our theory: first by looking at our previous RPGnet rating system, then by looking at the new system, and finally by by examining the data from these two systems and comparing their results. We’ve also run into some unexpected troubles along the way, and we’ll talk about that too.
The RPGnet Reviews System

RPGnet is our gaming site for tabletop roleplaying—games like Dungeons & Dragons and Vampire: The Masquerade. We purchased it in 2001 from the original owners. One of the benefits of RPGnet was that it had a very large community. As of today it sports one of the top-100 forums on the Internet, with over 1000 simultaneous users regularly logging in. However, because of its maturity, we also inherited many existing systems.
 One of these was the RPGnet Reviews System which gave individual users the ability to review gaming products—mostly role-playing games, but also board games, books, DVDs, and a smattering of related products.
One of these was the RPGnet Reviews System which gave individual users the ability to review gaming products—mostly role-playing games, but also board games, books, DVDs, and a smattering of related products.
Most of these reviews are submitted by average readers who just want to talk about a product that they like (or don’t), though a fair percentage are instead submitted by staff reviewers. (Overall at least 26% of our reviews are based on publisher “comp” copies, and thus may be considered largely professional, while the other 74% may or may not be.) The large community size of RPGnet applies to the Reviews System as well: currently it features 8,505 published reviews.
Looking at the RPGnet Reviews through our three filters we find the following:
Granularity. The ratings from our existing reviews aren’t as granular as we’d like. We have a theoretical scale of 2-10, but that’s based upon a Style rating of 1-5 and a Substance rating of 1-5.
| Rating | Style | Substance | % |
|---|---|---|---|
| 1 | 81 | 225 | 1.8% |
| 2 | 732 | 651 | 8.1% |
| 3 | 2364 | 1777 | 24.3% |
| 4 | 3618 | 3525 | 42.0% |
| 5 | 1709 | 2326 | 23.7% |
Approximately 90% of raters rate only with values of 3-5, and thus our scale is more limited than the 2-10 range would indicate. 42.9% of reviews further rate Style and Substance exactly the same, suggesting that not everyone sees a difference between these two elements. On the whole this scale isn’t as a bad as a singular 5-point scale, but it also isn’t a real 10-point scale, and the two orthogonal types of comparison don’t necessarily provide a coherent description of a product.
Distinctiveness. Conversely, the review ratings are fairly distinct because the Review System provides an explanation of what each rating number means. For example the five Substance ratings are: I Wasted My Money (1); Sparse (2); Average (3); Meaty (4); Excellent(5). The descriptions could be better, but hopefully they connect to some users in meaningful ways, and help them to rate consistently.
Statistics. Our review ratings have no statistical basis. These values are used entirely unfiltered.
On the whole, the existing RPGnet Reviews embodied slightly less than half of what we wanted to see in a rating systems: some improvement over a simple 5-point scale; some effort put into making individual ratings distinct; and nothing statistical.
There is room for improvement, however, as we’ll see when we analyze this system more fully.
The RPGnet Gaming Index
Our newer system is the RPGnet Gaming Index. It doesn’t supersede our Reviews, but instead offers a complementary look at the roleplaying field. The Index is essentially an RPG industry database. It contains individual entries for many different gamebooks—currently 5248—and allows registered users to rate each of them. Those ratings are then turned into averages by various mathematical formulas on a nightly basis and the roleplaying games in our index are then ranked.
The large size of RPGnet has allowed us to very quickly turn our ideas of a Gaming Index into reality. Just six months after release we have:
- 5248 well-written Index entries
- 5908 different editions
- 4240 authors
- 4478 covers
- 360 different game systems
- 345 series
- 10142 individual ratings
Most of the ratings are clumped around the best and worst games, with many less popular games unrated as of yet. Four different items have at least 80 ratings each (Call of Cthulhu, Exalted, Nobilis, and Unknown Armies). Our average rating is 6.79. Ratings above 7.82 are in the 99th percentile, ratings above 7.21 are in the 90th percentile, and ratings below 6.53 are beneath the 10th percentile.
(For more info on the creation of the RPG Index, and how to encourage user generated content, see Shannon’s articles, “Managing User Creativity”, Part One and Part Two.)
The RPGnet Index also handles some unusual situations, such as when a game book contains other game books as part of an anthology or compilation. For instance, the 8-book compilation In Search of Adventure has a composite rating of 6.57 which is partially based upon the individual adventures that make it up.
Granularity: The first thing we did was provide a 10-point scale for this new system.
Distinctiveness: We also made sure each point of the scale was clearly defined. Currently the points of our scale are: Worthless (1), Poor (2), Some Flaws (3), Almost Average (4), Average (5), Above Average (6), Good (7), Very Good (8), Outstanding (9), and One of the Best Ever (10).
We made some mistakes in our original release of our “distinctive” titles, and we discovered this had real effects on the user input, telling us that these title labels are meaningful to users.
First, we initially labeled 6 as “average”, to mirror the rating system for our existing Reviews, rather than setting 5 to be average. But as we noted in our first article, people like to be nice, and thus they tend to rate on the good side of a scale. Changing the label for our definition of average from 6 to 5 has slowly started dropping the average of all ratings down as a result (providing more breadth, a topic we’ll talk about more shortly).
Second, two of our original distinctive titles were at odds with the others. Our original “2” value said that the game had “a few useful elements” and our original “9” value said that it was the “best of the year”. The 2 was much more specific than any of our other terms and the 9 created a comparative query that was very different from anything else. Overall our ratings conformed to a bell curve centered between 6 and 7, but we saw very clear dropouts in our curve at 2 and 9, telling us that we’d made mistakes in those terms, and that people were less willing to use them as a result. Since we’ve made the change to our current set of titles those two discontinuities have disappeared.
Statistics. Finally, we fully integrated statistics into our new Index by using two main methods: bayesian weights and trust.
We explained bayesian weights pretty fully in our previous article. Here’s what we said then:
The idea behind a bayesian average is that you normalize ratings by pushing them toward the average rating for your site, and you do that more for items with fewer ratings than those with more ratings. The basic formula looks like this:
b(r) = [ W(a) * a + W(r) * r ] / (W(a) + W(r)]r = average rating for an item
W(r) = weight of that rating, which is the number of ratings
a = average rating for your collection
W(a) = weight of that average, which is an arbitrary number, but should be higher if you generally expect to have more ratings for your items; 100 is used here, for a database which expects many ratings per item
b(r) = new bayesian rating
Say three “shill” users had come onto your site and rated a brand new indie film a “10” because the producer asked them to. However, you use a bayesian average with a weight of 100, and thus 3 ratings won’t move the movie very far from the average site rating of 6.50:
b(r) = [100 * 6.50 + 3 * 10] / (100 + 3)b(r) = 680 / 103b(r) = 6.60
We implemented bayesian weights exactly as we’d detailed, but with a lower weight of 25. Since then we’ve accrued over 10,000 ratings in the database, and we can probably start thinking about cranking that weight up, another topic we’ll return to.
Our trust-based algorithms suggest that some ratings are better than others, and should thus be more trusted (and thus more weighted when we calculate the average rating of an item). Though bayesian weights have been used before, we’re not aware of other systems that weight ratings based on trust.
The calculation of trust is very simple:
Weight = 0 if #ratings(user) <= 2
Otherwise Weight = #ratings(user) / 50 to a maximum of 2
Weight *= 2, to a maximum of 4, if the user included a comment
This was based on the idea that the average good rater would rate 25 different items and the average great rater would rate at least 50. Additionally, we believed that ratings with comments were more likely to be thoughtful than those without.
That, overall, is a quick picture of what we’ve done with the RPGnet Gaming Index. Some of these ideas were laid out from the start, and others have been tuned as we progressed.
So how did we do, particularly in comparison to our existing RPGnet Reviews System?
The Comparison
One of our goals in improving rating systems has been to widen the range of possible input. As we noted earlier we discovered that 90% of our RPGnet Reviews Ratings were in the 3-5 range, and only 10% in the 1-2 range.
Generally, we can measure the success of widening a range by seeing whether the average rating of a database moves toward the true average. For the purposes of a 10-point scale from 1-10, that’s a desired value of 5.5. That generally means we’re looking for our average rating to decrease because people tend to rate high.
The following table compares the average results of Reviews ratings and Index ratings.
| Database | Average |
| Converted Reviews | 7.25 |
| Massaged Reviews | 7.29 |
| Unweighted Index | 7.10 |
| Weighted Index | 6.78 |
Here’s what the categories in the above chart represent:
Converted Reviews: The Style + Substance of the Reviews, converted from its 2-10 scale to a 1-10 scale:
$rating = avg($style) + avg($substance);
$rating = ($rating * 1.125) - 1.25;
Massaged Reviews: The Style + Substance of the Reviews, with Substance given double weight over Style because we think that more closely reflects the intentions of the reviewer, converted from its 2-10 scale to a 1-10 scale:
$rating = (average($style) + 2*average($substance))/1.5;
$rating = ($rating * 1.125) - 1.25;
Unweighted Index: Index ratings exactly as users have entered into our Gaming Index:
$rating = average($index-rating);
Weighted Index: Index ratings adjusted by the weight of each individual rating, which is based on user trust and inclusion of comments:
$rating = average($index-rating*$index-weight)/average($index-weight);
Our average rating—which is our criteria for success—decreased somewhat from the Reviews System to the Gaming Index and it decreased much more dramatically when we introduced our trust systems.
The following chart shows the a typical example of how review and index ratings differ, using the venerable Dungeons & Dragons Player’s Handbook as an example:
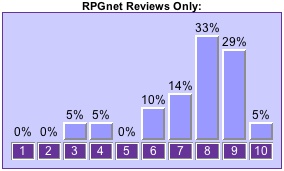
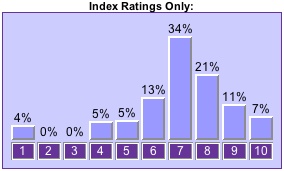
For this book the median ratings from reviews-only is 8, and the median from index-only is 7. A one-to-two point drop in median rating from reviews to index was consistent in all of our most-rated games other than those which were a rated a “10” in both places.
We believe that this initial success of our unweighted Gaming Index can be attributed to the slightly better granularity—a 10-point scale versus two 5-point scales—and our improved distinctiviness—based on better naming of the rating levels. The veracity of this will ultimately be played out as the Index grows.
However we have no doubt that our statistical approach to the index data, when we moved from our unweighted Index to our weighted Index, is providing even better results. We had theorized that users who input more and who include comments would provide “better” data, and by our criteria of the average of the ratings moving toward 5.5 that seems to be borne out. The following table looks at the information a bit more precisely, by comparing average ratings as total number of ratings increases over several ranges:
| # of Ratings | Average w/Comment | Average w/o Comment |
| 1-2 | 8.55 | 8.88 |
| 3-24 | 8.08 | 8.16 |
| 25-49 | 7.32 | 7.11 |
| 50-99 | 7.14 | 7.03 |
| 100+ | 6.17 | 6.99 |
This table fairly definitively shows that base maxim: that the breadth of the ratings, and thus their quality, increases the more ratings a user makes. The improved quality of ratings with comments is less definitive. Among the vast mass of users the two values are pretty close, and sometimes the reverse of what we expect, but for the best and the worst users, ratings with comments seem to be better than those without. This latter point is another one that we’ll have to continue to monitor as the Index grows beyond its current total of 10,000 ratings.
The other major element of our statistical approach to the Index is our bayesian weight. The following chart shows a top-ten chart for roleplaying games calculated via four different methodologies: our Reviews; our Index with no weighting; our Index with a 25 bayesian weighting (as it currently stands); and our Index with a 50 bayesian weighting:
| # | Reviews-Only | 0-weight Index | 25-weight Index | 50-weight Index |
| 1 | Delta Green: Countdown | The Chronicles of Talislanta | Delta Green: Countdown | Delta Green |
| 2 | Nobilis | Wildside | Spirit of the Century | Delta Green: Countdown |
| 3 | Castle Falkenstein | Devil’s Due | Delta Green | Unknown Armies |
| 4 | Vimary Sourcebook | Lodges: The Faithful | Unknown Armies | Call of Cthulhu |
| 5 | Liber Servitorum | Apocalypse | Call of Cthulhu | Nobilis |
| 6 | Ork! | Earthdawn Gamemaster’s Compendium | Nobilis | Spirit of the Century |
| 7 | GURPS Russia | Into the Badlands | Pendragon | Over the Edge |
| 8 | GURPS Reign of Steel | Earthdawn Player’s Compendium | Over the Edge | Pendragon |
| 9 | Cudgel’s Compendium | Chronicle of the Black Labyrinth | Mutants & Masterminds | Mutants & Masterminds |
| 10 | Corum | The Spell Book | Pulp Hero | Vimary Sourcebook |
We actually did do a little bit of statistical analysis on the Reviews because on our first try to produce this chart we got a random clump of reviews that were 5/5 from a much larger pool, so we further ordered them by descending total count of reviews, and as a result you’re seeing a better selection of ranked reviews than a truly unstatistical sampling would allow. We did the same for the unweighted Index (which clumped a number of results at “10”), except we further ordered items at the same weight by decreasing number of views (another statistical decision).
Clearly, deciding which of these lists is “right” is a much more subjective measure than the mathematical analysis we were able to apply to earlier problems. However, most roleplayers would tell you that the unweighted Reviews and Index lists are terrible. The top 5 items in the Reviews list actually aren’t bad for a starting list of good games—but only because we did the aforementioned statistical ordering. Before that we just had a random listing of gaming items. Even with our attempts at quickie statistical analysis the unweighted Index is still quite bad, with only Talislanta regularly showing up on other “best” lists.
The problem is the ability of one person to come in and rate an item a “10” (or a “5”/”5”), thereby making that item more highly rated than any item which has an actual consensus of ratings. Of our unweighted top Reviews only the top three had more than 2 reviews and the rest had 2. Not surprisingly those top three were the best fits to a typical top-ten list. Of the unweighted Index only the top three had more than 1 rating, and the rest had 1. Our single good pick was in those top three.
Our 25-weight Index, which is what we currently use, has been generally accepted by the RPGnet community as a good marker of what’s good and what’s not. However there have been two items on it which some percentage of people disagree with: Spirit of the Century and Pulp Hero. It’s instructive to see that when we increase to a 50-weight Index Spirit of the Century drops (even more notably than depicted here, because its actual rating changes from .01 from first place to .16 from first place) and Pulp Hero disappears entirely.
The questions of what to set your bayesian weight to, when to increase it, and what maximum value to set it to are all relatively unstudied and thus we don’t have good answers to them. As we pass 10,000 ratings we’re considering upping the bayesian value to 50. We expect that 100 will be our ultimate value when the Index is fully mature, however if we increase the weight too far an older, less rated game will never be able to get enough weight to get out of the doldrums.
Conclusion
We’re by no means done with this ratings experiment. Though we’ve pleased and impressed with the growth of the RPGnet Index thus far, by next year we hope that the Index will include the vast majority of all games in print (as opposed to somewhat less than half now) and that our 10,000 ratings will grow to 50,000 or more. This will allow us to offer even more definitive answers to our questions.
In the meantime we’re still mucking with our statistics and facing new problems. Some of the newest:
- What to do about drive-by ratings: Our trust algorithm does a good job of making drive-by ratings, where a publisher points his audience to an item in our site, mostly irrelevant, but there’s some concern that they could have more effect in the long run.
- How to incorporate our review ratings in our index ratings: It seems a shame to waste the thousands of reviews that have been written—and indeed currently they’re calculated into a composite rating we use in the Index—but we’re realizing that people have very different purposes for writing reviews and inputing ratings, which may result in some of the upward skew we see on the review side of things. Ultimately we need to decide whether they’re just too different or whether our statistical massaging is enough to incorporate those reviews into a composite Index rating.
- How to pick some of our numbers: As we already noted we don’t have good formulas for when to choose which bayesian weights. Likewise we’ve been guessing at which values to use for the trust-based weighting of our raters. Originally we set our desired rating count to 100 for good rater and 200 for great raters, but we’ve since dropped those to 50 for good and 100 for great based upon the real numbers of ratings that users were making. Again, we’d prefer to derive an actual formula for this type of calculation
Shannon has discussed some of these issues more in his recent article More Thoughts Abour Ratings.
Despite unanswered questions, we still feel good about the basic ideas we laid out in our article last year. We have no doubt that giving our ratings a statistical basis has dramatically improved them and evidence thus far suggests that both granularity and distinctiveness have been helpful as well.
Related articles from this blog:
Related articles from Shannon Appelcline’s Trials, Triumphs & Trivialities:
Comments
URL: 0-10 scale is too large for most relevant human ratings systems. maybe i should pull the psych papers, but people tend to do a 1-5 or 0-5 scale better. it’s a sign of immaturity to only use the endpoints.
Grumpy 2007-12-18T10:24:24-07:00
Life With Alacrity
© Christopher Allen